接續昨天的監控介紹和 Day24 的實作篇,今天就要來介紹如何使用開源工具Prometheus和Grafana來監控vLLM的一些硬體與推理指標,最後實作一個非常基礎的dashboard 📊。
因為這篇也是一堆圖,所以先放大綱。
🔍 章節大綱
- vLLM Production Metrics 介紹 📘
- Docker Compose 安裝 Prometheus 和 Grafana 🐳
- 串接 + 拉 dashboard 📊
- vLLM logs 介紹 📖
⚠️ 注意:因為筆者在infra時期只懂皮毛,所以這篇的方法基本上都是GPT-4o老師教的,僅供參考。

(圖源: Medium,雖然dashboard看起來很漂亮,但後面的pipeline也是很重要的)
官方文件有提供一個監控的方法,在OpenAI compatible API server的/metrics endpoint,其中監控指標vLLM用英文都取名得很白話,但同時也歡迎參考 Day4。
假設你開了一個vLLM服務在http://localhost:8000/,這時如果curl http://localhost:8000/metrics會發現有很多這種格式的回應:
# HELP vllm:num_requests_running Number of requests currently running on GPU.
# TYPE vllm:num_requests_running gauge
vllm:num_requests_running{model_name="yentinglin/Llama-3-Taiwan-8B-Instruct-128k"} 0.0
這種資料格式是「Exposition formats」,是prometheus的資料格式。
# HELP是一個可選的說明行,用來解釋這個metric的作用。# TYPE用來指定這個metric的類型。Prometheus中常見的metric類型包含:
vllm:num_requests_running是這個metric的名稱。{model_name="yentinglin/Llama-3-Taiwan-8B-Instruct-128k"}是這個metric的label。
0.0是這個metric當前的值,表示在這個模型上請求數量是0。⚠️ 其他詳細介紹和使用方式請深入研究Prometheus和PromQL!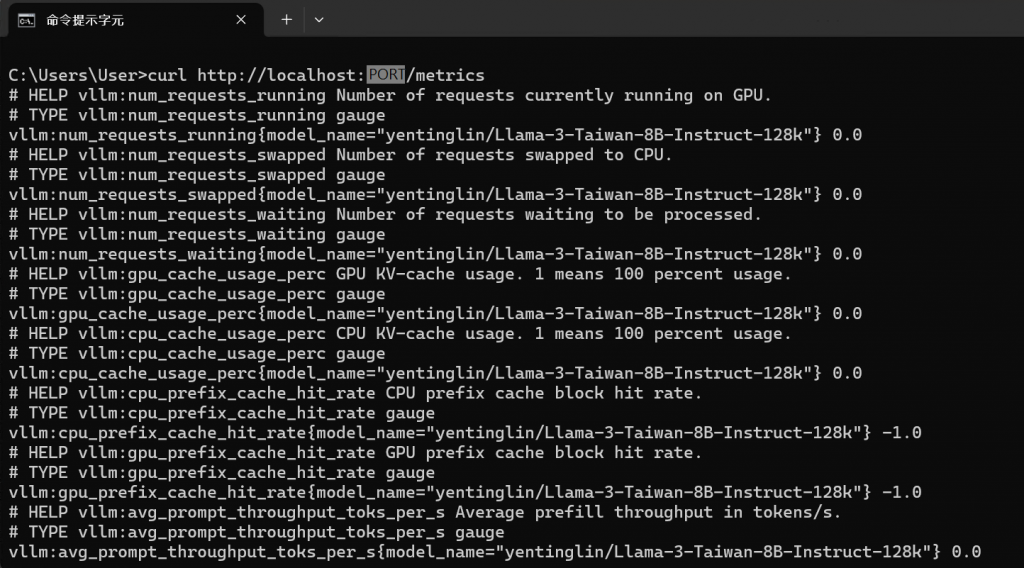
mkdir prometheus-grafana
cd prometheus-grafana
prometheus.yml和docker-compose.yml兩個文件。prometheus.yml
global:
scrape_interval: 15s # Prometheus每15秒拉取一次資料
scrape_configs:
- job_name: 'custom-metrics' # 任務名稱,可以自定義
static_configs:
- targets: ['特定IP:8000'] # 這裡填寫你要監控的metrics地址,例如'127.0.0.1:8000',不用加上/metrics
docker-compose.yml
version: '3.7'
services:
prometheus:
image: prom/prometheus:latest # 用最新版本的Prometheus
container_name: prometheus
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml # 把本地的prometheus.yml映射到容器內
ports:
- "9090:9090" # 把容器內的9090 port映射到電腦
restart: unless-stopped # 如果服務出問題自動重啟
grafana:
image: grafana/grafana:latest # 用最新版本的Grafana
container_name: grafana
ports:
- "3000:3000" # 把容器內的3000 port映射到電腦,這是Grafana的Web介面
restart: unless-stopped
docker-compose up -d
可以看到prometheus和grafana的ID都有成功建立docker了。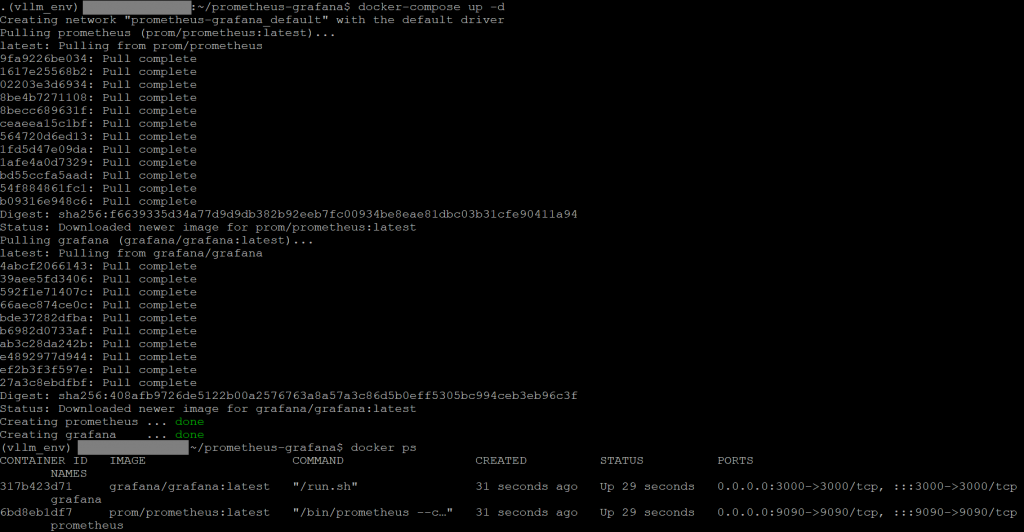
打開Grafana http://localhost:3000 ,預設帳密是admin@admin,第一次登入會需要改密碼。
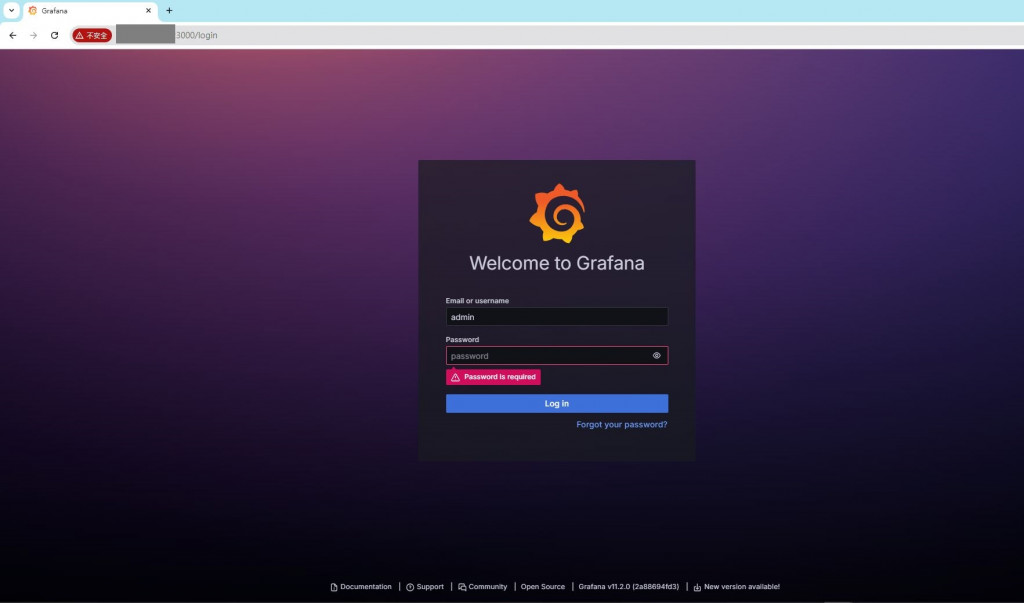
登入之後找到Connection > Data sources > Add new data source
選擇prometheus,之後把prometheus的URL http://localhost:9090/填上去,最下面Save & test。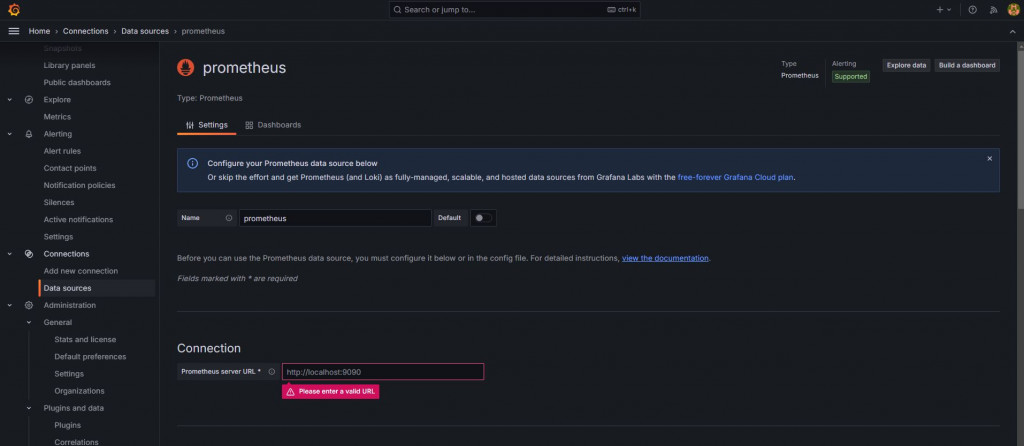
再來就可以直接建立dashboard了。
⚠️ 再度提醒,筆者是超級Grafana菜鳥,這邊請參考專門撰寫Grafana的系列來拉dashboard。
稍微介紹一下欄位。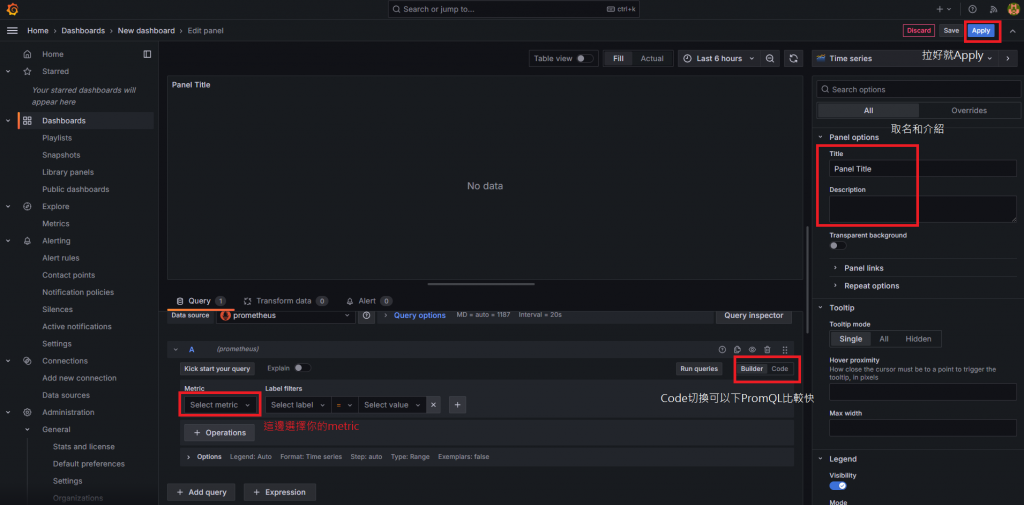
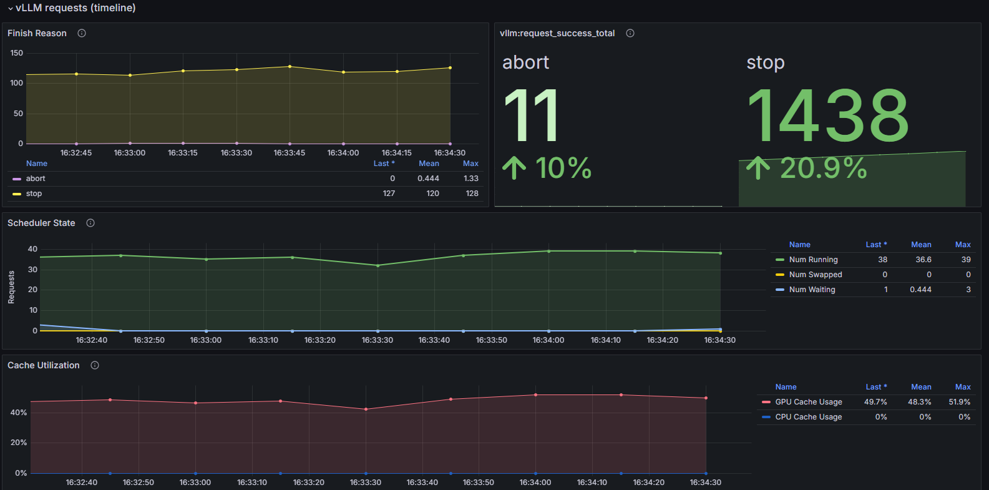
下圖是筆者隨便拉的,偷偷更新一個好看的版本QQ
右邊的request_success_total會因為finished_reason區分成不同的累加,這些都可以透過PromQL去做顯示上的調整,顯示上顏色的調整就看個人。
建立dashboard時下面的值不知道要填啥,可以從Explore > Metrics去看。
截圖的時候因為才剛開起來,還沒有vLLM的request,所以除了counter之外的metric都是no data。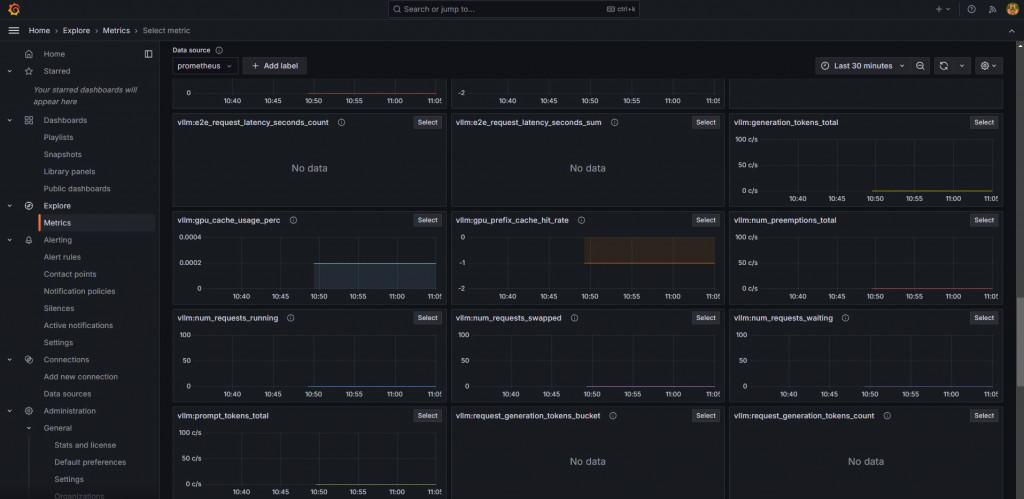
筆者這邊用postman Runner瘋狂打5分鐘就有很多資料了!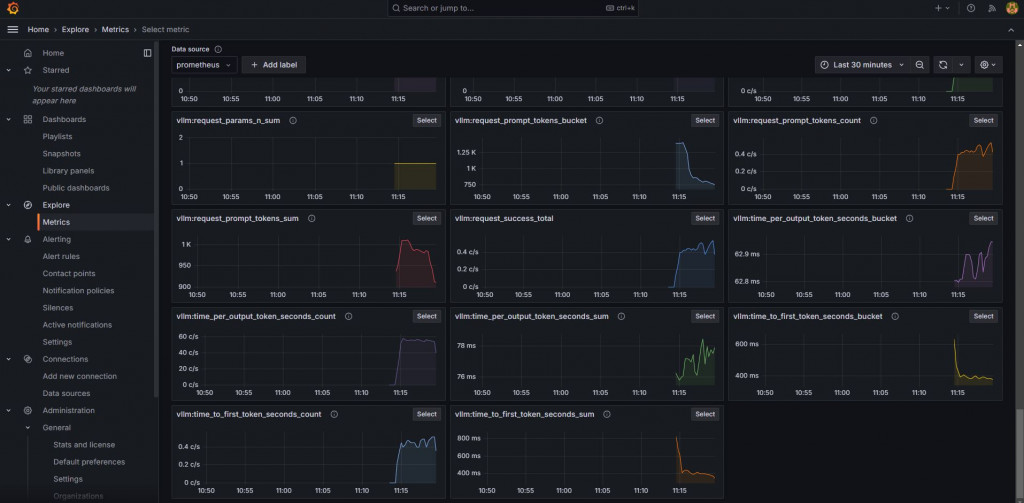
🐞 如果一直都沒有資料,想要debug確定你的prometheus有沒有問題:
可以先下docker logs prometheus檢查有沒有問題。
如果還是找不到,可以去http://localhost:9090/介面看看State有沒有DOWN。筆者之前腦霧忘記自己改了vLLM的port,但prometheus沒改就直接DOWN沒資料了,還花了一堆時間找原因ಥ_ಥ。
(另外需注意prometheus資料儲存時間設定,若沒特別設定,會存15天內的資料。)
官方文件同時也有提供一個vLLM logs放置的位置,這邊以官方給的例子來介紹:
tail ~/.config/vllm/usage_stats.json
{
"uuid": "fbe880e9-084d-4cab-a395-8984c50f1109",
"provider": "GCP",
"num_cpu": 24,
"cpu_type": "Intel(R) Xeon(R) CPU @ 2.20GHz",
"cpu_family_model_stepping": "6,85,7",
"total_memory": 101261135872,
"architecture": "x86_64",
"platform": "Linux-5.10.0-28-cloud-amd64-x86_64-with-glibc2.31",
"gpu_count": 2,
"gpu_type": "NVIDIA L4",
"gpu_memory_per_device": 23580639232,
"model_architecture": "OPTForCausalLM",
"vllm_version": "0.3.2+cu123",
"context": "LLM_CLASS",
"log_time": 1711663373492490000,
"source": "production",
"dtype": "torch.float16",
"tensor_parallel_size": 1,
"block_size": 16,
"gpu_memory_utilization": 0.9,
"quantization": null,
"kv_cache_dtype": "auto",
"enable_lora": false,
"enable_prefix_caching": false,
"enforce_eager": false,
"disable_custom_all_reduce": true
}
而這些資料也可以整合進ELK Stack當中,再依照需求去做更進階的分析。同樣地,如果想學這些設定,請再去閱讀相關的系列XDD
- 也許留著這些會有企業感到不舒服,因此官方也有提供不要存這些資料的方法。
- 設置環境變量
VLLM_NO_USAGE_STATS=1或DO_NOT_TRACK=1。- 或是建立一個文件
~/.config/vllm/do_not_track來禁止資料收集。
10/8補充:後來從這個discussions發現vLLM官方dashboard藏在這裡!!
直接下載grafana.json再import到grafana上就可以用啦,連一分鐘都不用就設定好了,好快好潮!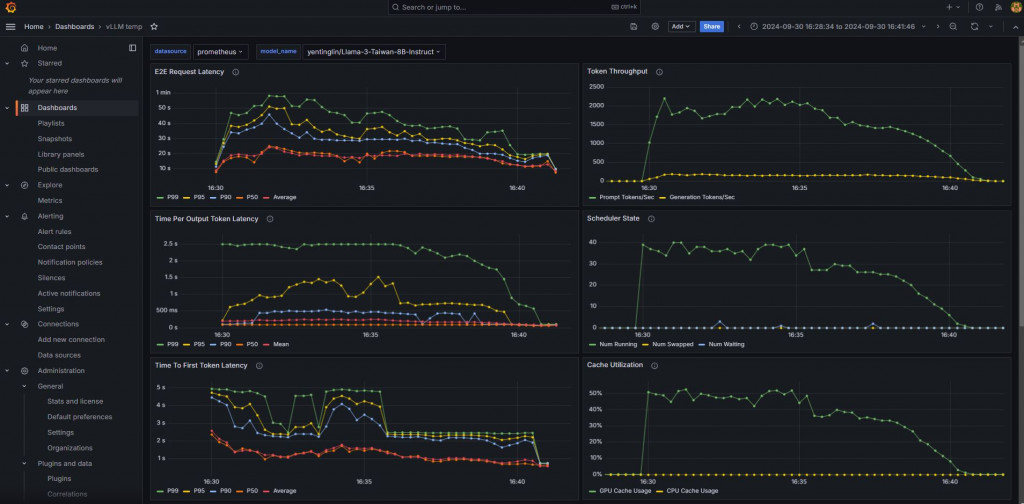
其他也有別人做的,用InfluxDB抓GPU相關資料的dashboard,看起來也滿不錯的,但自己拉也是很好玩,拉了一個禮拜後終於找回手感了(???)
11/15補充:筆者後來去惡補了Observability Three Pillars,也就是Metrics、Logs、Traces。而目前這章節主要是Metrics的監控和視覺化,其餘Logs和Traces依照各專案可以去做設定。在查了許多專門做LLM monitoring & observability的公司產品後,大概發現了常見的內容:
而在這章節的教學中,比起其他人的產品,更多了server收到的requests分析,停止原因,GPU Cache等資訊。
很多公司產品都是以Traces為主,附加一些包含基本Metrics的dashaboard,整體而言看起來若是專案不大,也可以考慮自行建設可觀測系統。
關於LLM監控的詳細介紹,Confident AI這篇文章寫的不錯,若讀者有興趣可以看一下。
如果有在使用llama_index的朋友,也許有發現官方文件已經有一些可以連動的Observability方法,也可以嘗試看看。
這一章簡單介紹了實作步驟,學習如何從零開始,利用使用Prometheus和Grafana來簡單建立一個極為基礎的LLM監控系統。但在實踐中,無論是配置Prometheus 🧩、撰寫有用的PromQL查詢 🧑🔬,還是設計自定義的dashboard 🛸,都需要深入的學習和持續的實踐。
技術領域沒有捷徑 🚧,尤其是這些名稱就可以成為一本書籍的技術,更是要腳踏實地學習,學習和應用過程中不可避免地會發現自己的不足,這也是不斷進步的契機 🔄。
對於有興趣進一步探索LLMOps監控的讀者,這是一個充滿挑戰與回報的領域 💡,歡迎您一同踏入這個技術的大坑 🕳️,並期待未來持續的成長與學習 📈!
(圖源: 梗圖倉庫,請把摺紙換成拉dashboard)
OK,以上是GPT-4o用文言文修過的總結,筆者真正的OS是......雖然要架起來是超快的也沒啥問題,但拉那個dashboard超難拉啊啊啊,拉了整天還是拉不出什麼可以看的內容,早知道以前認真一點冒著被嘴的風險多問學長們一些厚臉皮問題了啦RRRR。
如果這系列29天以來覺得有一些收穫,也歡迎來閱讀明天的聊天總結篇章!!

(圖源: 自製,就......一點點而已)